
AI की दुनिया में अगर इमेज, वीडियो, स्कैन, या कैमरा फ़ीड समझनी है—तो सबसे पहले नाम आता है CNN (Convolutional Neural Network) का। बहुत लोग पूछते हैं, “ये Convolution होता क्या है? Kernel, Filter, Stride, Padding—इतना सब क्यों?”
चिंता छोड़िए 😊 मैं (आपकी दोस्ताना टेक-दीदी) इसे बहुत आसान, घर-परिवार वाली मिसालों से समझाऊँगी—ताकि आप पढ़कर बोलें, “अरे, इतना सिंपल था!”

CNN क्यों ज़रूरी है? (समस्या समझें)
विषयसूची
इमेज में लाखों पिक्सेल होते हैं। हर पिक्सेल को नियम लिखकर समझाना नामुमकिन है—यानी “अगर-तो” वाले रूल्स यहाँ काम नहीं आते। CNN इमेज से पैटर्न (किनारे, टेक्सचर, आँखें, नाक, पहिए, रोड-लाइन) खुद सीख लेता है—और यही इसे इमेज/वीडियो के लिए सुपरस्टार बनाता है।
रोज़मर्रा की मिसाल:
- फ़ोन कैमरा का Portrait Mode: बैकग्राउंड ब्लर करने से पहले चेहरा/सब्जेक्ट पहचानना।
- Face Unlock: आपका चेहरा पहचानना।
- गैलरी में “People, Cats, Sunset” जैसे ऑटो-एल्बम बनना—सब CNN जैसी तकनीकों से।

Convolution क्या है? (Filter/Kernels with Example)
Convolution का मतलब—छोटे-छोटे फ़िल्टर/Kernel (जैसे 3×3, 5×5) इमेज पर स्लाइड करते हैं और महत्वपूर्ण पैटर्न उठाते हैं:
- Edge Filters: किनारे/बॉर्डर पकड़ना (जैसे चेहरे की outline)
- Texture Filters: टेक्सचर पकड़ना (बाल, कपड़े के पैटर्न)
- Shape Filters: आँख, कान, पत्ती, पहिया जैसी स्ट्रक्चर संकेत
रसोई analogy:
इमेज को आटे की लोई समझिए। आप चक्की (filter) से इसे निकालते हैं—महीन particles अलग, मोटे अलग। Convolution भी इसी तरह useful features छाँटकर आगे भेजता है।
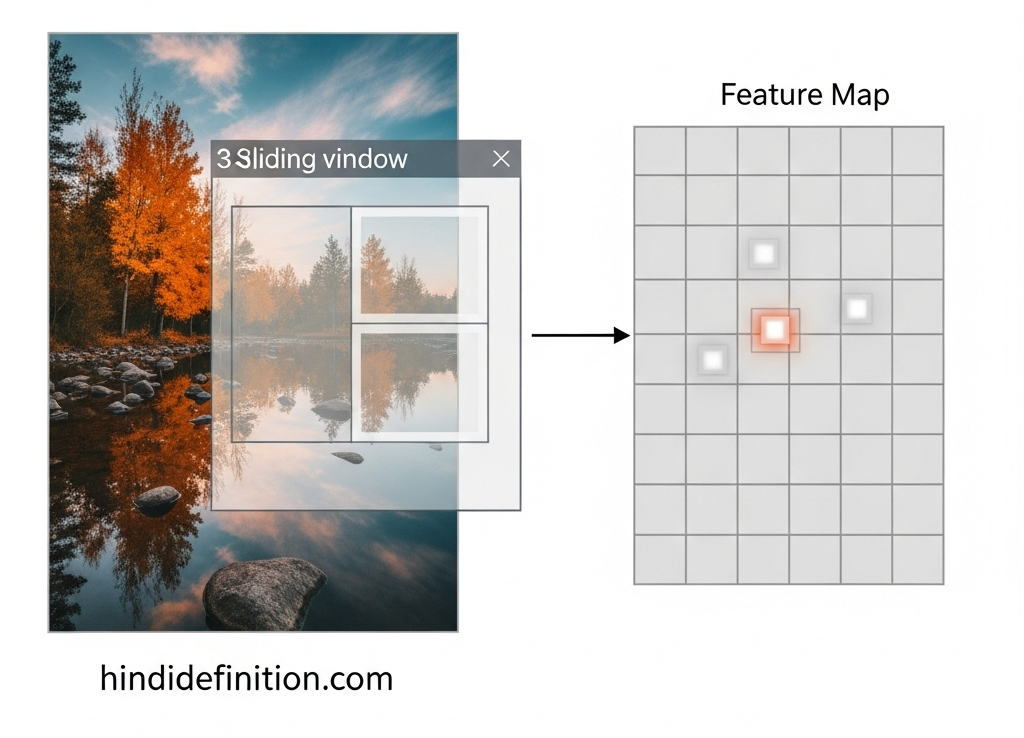
Feature Map, Stride, Padding—3 शब्द, एक तस्वीर
- Feature Map: फ़िल्टर से निकला नया नक्शा—जिसमें वही चीज़ें हाईलाइट हों जो फ़िल्टर ढूँढ़ रहा था (जैसे edges)।
- Stride: फ़िल्टर कितने-कितने पिक्सेल कूदकर चलेगा (1, 2, …)—ज़्यादा stride → छोटा output।
- Padding: इमेज के किनारों पर ‘zero’ जोड़कर साइज संभालना, ताकि फ़िल्टर बॉर्डर तक अच्छे से काम करे।
Example:
मान लें 32×32 इमेज पर 3×3 फ़िल्टर, stride 1, padding 1 → Output भी लगभग 32×32 रहेगा।
यह ऐसे समझें—चक्की किनारे तक पहुँच सके, इसलिए थोड़ा extra आटा (padding) चारों तरफ लगाते हैं।
Pooling: साइज छोटा, फीचर मजबूत
Pooling (जैसे Max Pooling 2×2) इमेज/feature map का साइज कम करती है, लेकिन सबसे जरूरी संकेत बचा लेती है।
- Max Pooling: 2×2 के ब्लॉक में सबसे बड़ा वैल्यू—यानी सबसे स्ट्रॉन्ग फीचर—आगे बढ़ता है।
- फायदा: साइज घटता है → कम computation; साथ ही नॉइज़ कम, फीचर robust।
मिसाल: फोटो छोटा करें, पर मोस्ट इम्पोर्टेन्ट डिटेल बने रहें—यही pooling का भाव है।

CNN की बेसिक आर्किटेक्चर (लेयर दर लेयर)
- Input (H×W×C): H=ऊँचाई, W=चौड़ाई, C=चैनल (RGB=3)
- Conv + ReLU: Convolution से फीचर; ReLU से non-linearity (तेज़/स्टेबल ट्रेनिंग)
- Pooling: साइज घटाना, फीचर condensed करना
- (कभी-कभी) BatchNorm/Dropout: ट्रेनिंग stable और overfitting कम
- Flatten + Fully Connected (Dense): अंत में क्लास-स्कोर निकालना
- Softmax: probabilities में बदलना (जैसे Cat=0.8, Dog=0.1, Bird=0.1)
याद रहे: शुरू की लेयर्स लो-लेवल फीचर्स (edges/texture) पकड़ती हैं; गहराई में जाकर हाई-लेवल (आँख/नाक/शेप/ऑब्जेक्ट पार्ट) पकड़ती हैं।
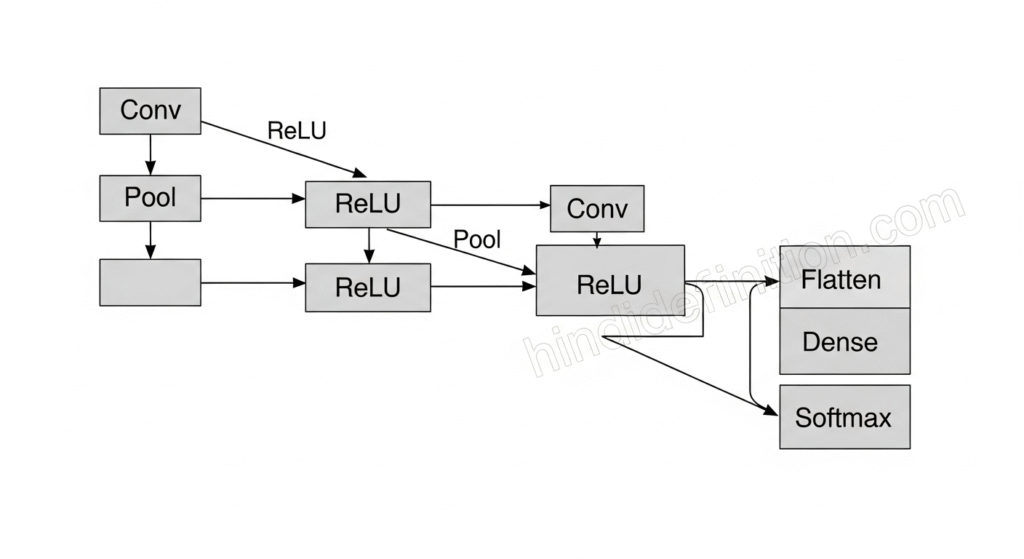
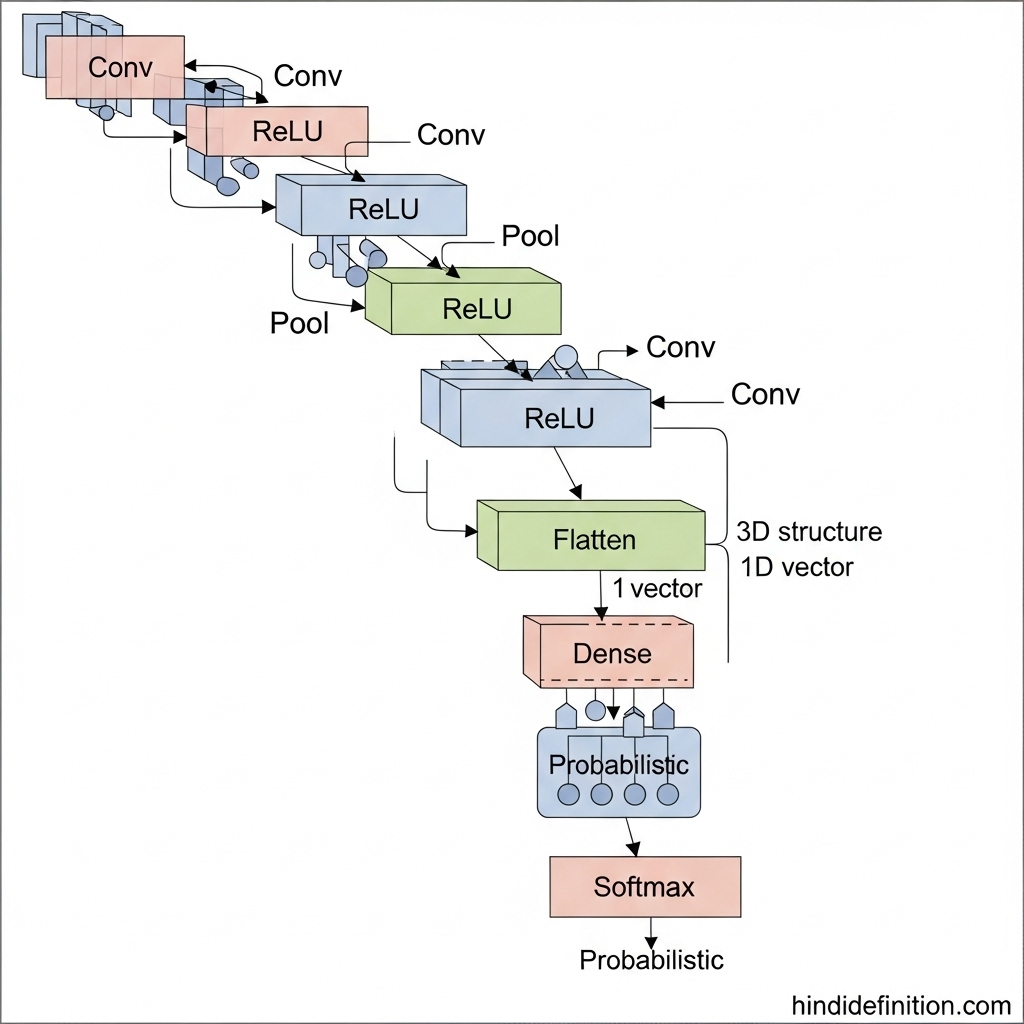
Training कैसे होता है? (Simple Flow)
- Loss Function: Cross-Entropy (क्लासिफिकेशन में आम)
- Optimizer: SGD/Adam — weights सीखते हैं कि कौन-सा फ़िल्टर कितना ज़रूरी
- Backpropagation: गलती (loss) देखकर फ़िल्टर अपडेट—अगली बार पहचान और बेहतर
उदाहरण:
पहली बार मॉडल बिल्ली को कुत्ता समझा (loss ज़्यादा)। धीरे-धीरे फ़िल्टर ऐसे सीखते हैं कि बिल्ली की मूँछ, आँख, कान जैसे संकेत सही पकड़ें।
Overfitting और उससे बचाव
- समस्या: मॉडल ट्रेन डेटा को ‘रट’ लेता है; नए फोटो पर ग़लती।
- उपाय:
- Data Augmentation (रोटेशन, क्रॉप, फ्लिप, कलर-जिटर)
- Dropout, Weight Decay (L2)
- Early Stopping, More diverse data
माँ की सीख वाली मिसाल:
अगर बच्चा सिर्फ़ एक ही सवाल रटता है, परीक्षा में नए सवाल पर अटकता है। अलग-अलग तरह की प्रैक्टिस (augmentation) से समझ बढ़ती है।

Transfer Learning: कम डेटा में बड़ा काम
हर कोई शुरू से CNN ट्रेन नहीं करता—pretrained models (जैसे VGG, ResNet, MobileNet, EfficientNet) बड़े डेटासेट (जैसे ImageNet) पर सीखे होते हैं।
- फायदा: कम डेटा और कम समय में अच्छी परफॉर्मेंस।
- कैसे?
- Feature Extractor: आख़िरी लेयर्स हटाकर अपनी नई क्लासेस के लिए नया head लगाएँ।
- Fine-tuning: कुछ गहरी लेयर्स अनफ्रीज़ कर के थोड़ी ट्रेनिंग करें—डोमेन के हिसाब से ट्यून हो जाएगा।
रिलेटेबल बात:
जैसे पहले से पढ़े-लिखे स्टूडेंट को बस syllabus बदलकर थोड़ा सा नया सिखाना—समझ जल्दी बैठती है।
CNN कहाँ काम आता है? (Use-Cases)
- Image Classification: बिल्ली vs कुत्ता, रोग ग्रेडिंग, प्रोडक्ट कैटेगरी
- Object Detection: इमेज में क्या है और कहाँ है (Faster R-CNN, SSD, YOLO)
- Image Segmentation: हर पिक्सेल को क्लास देना (U-Net, Mask R-CNN)
- OCR: स्कैन से टेक्स्ट निकालना (किताब, फॉर्म)
- Medical Imaging: एक्स-रे, MRI, CT में संकेत पकड़ना
- Autonomous Driving (Perception): लेन, साइनेज, पैदल यात्री पहचान
CNN vs Vision Transformers (ViT) – संक्षेप तुलना
- CNN: लोकल पैटर्न (edges/texture) पकड़ने में माहिर; कम compute पर भी बढ़िया; क्लासिक और भरोसेमंद।
- ViT (Transformer for Vision): Attention से पूरे इमेज की global dependency अच्छे से कैद; बहुत डेटा/compute पर दमदार।
प्रैक्टिकल सलाह: छोटे/मध्यम प्रोजेक्ट्स व सीमित compute में CNN बढ़िया; बड़े डेटा/रिसर्च-ग्रेड सेटअप में ViT आकर्षक विकल्प है।
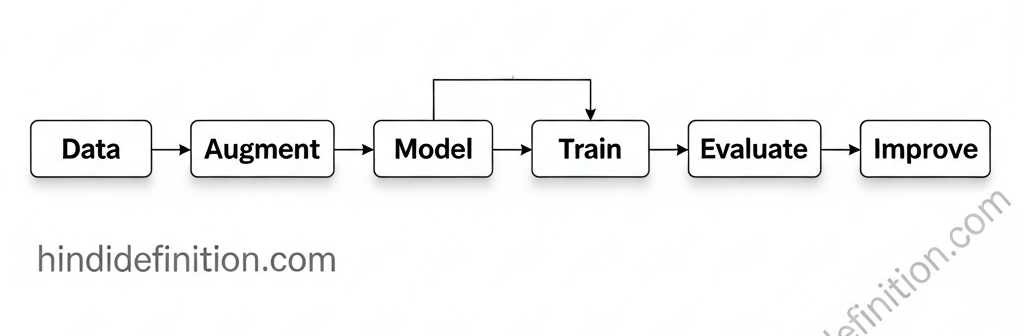
Mini Blueprint: “Cats vs Dogs” क्लासिफायर कैसे बनता?
- डेटा इकट्ठा: 2 फ़ोल्डर—
cats/,dogs/ - Augmentation: फ्लिप, क्रॉप, रोटेशन
- Model:
Conv→ReLU→Pool×2–3 →Flatten→Dense→Softmax - Train: Cross-Entropy + Adam, 10–20 epochs
- Eval: Accuracy + Confusion Matrix
- Improve: Transfer Learning (MobileNet/ResNet) आज़माएँ
FAQs (बार-बार पूछे जाने वाले सवाल)
Q1. CNN और साधारण Neural Network (MLP) में क्या फर्क है?
A. MLP फ्लैट फीचर्स पर काम करता है; CNN स्पेशल (H×W×C) स्ट्रक्चर का फायदा उठाता है—लोकल पैटर्न पकड़ने में मास्टर।
Q2. Kernel/Filter साइज कैसे चुनें?
A. 3×3 बहुत कॉमन और प्रभावी है; 1×1, 5×5 भी टास्क/कम्प्यूट के हिसाब से। आजकल कई 3×3 स्टैक करके बड़े receptive field बनाते हैं।
Q3. Max Pooling vs Average Pooling?
A. Max Pooling strongest फीचर बचाता है, detection/edges में अच्छा; Average Pooling स्मूदनिंग करता है—कब-कहाँ चाहिए, टास्क पर निर्भर।
Q4. Transfer Learning कब करें?
A. जब अपने पास कम डेटा/कम्प्यूट हो—pretrained models से तेज़ और अच्छे नतीजे मिलते हैं।
Q5. Object Detection और Segmentation में CNN की भूमिका?
A. Backbone फीचर-एक्सट्रैक्टर अक्सर CNN ही होता है; आगे detection/segmentation हेड अलग जोड़े जाते हैं।
Q6. क्या केवल CNN से ही सब हो जाता है?
A. नहीं। आज Vision Transformers, hybrid आर्किटेक्चर भी चलन में हैं। चुनाव डेटा, compute और लक्ष्य पर निर्भर है।
निष्कर्ष
CNN इमेज/वीडियो के छोटे-छोटे पैटर्न पकड़कर बड़ा समझदार फैसला लेना सिखाता है। Convolution, Pooling, Stride, Padding—ये सब केवल शब्द नहीं, बल्कि वो ईंटें हैं जिनसे इमेज-इंटेलिजेंस की इमारत खड़ी होती है। कम डेटा में भी Transfer Learning से आप बढ़िया मॉडल बना सकते हैं। और हाँ—छोटे प्रोजेक्ट से शुरुआत करें, धीरे-धीरे महारत अपने-आप बनती जाएगी। 🚀










