
AI सुनते ही सबसे ज़्यादा बार जो शब्द कानों में आता है, वो है Neural Network. लेकिन ये होता क्या है? कैसे काम करता है? और Deep Learning, CNN, RNN, Transformer जैसे नाम कहाँ फिट होते हैं? आज मैं (आपकी टेक-दीदी 😊) इसे बिलकुल रोज़मर्रा की भाषा में, छोटे-छोटे उदाहरणों के साथ समझाऊँगी—ताकि आप पढ़कर बोलें, “अरे, इतनी आसान चीज़ थी!”

Neural Network की ज़रूरत क्यों पड़ी?
विषयसूची
कई समस्याएँ बहुत जटिल होती हैं—जैसे फोटो में बिल्ली पहचानना, आवाज़ समझना, या हिंदी वाक्य का अर्थ पकड़ना। पारंपरिक नियम-आधारित प्रोग्रामिंग में हर स्थिति के लिए ‘यदि-तो’ नियम लिखना लगभग नामुमकिन है। यहीं Neural Network (NN) काम आता है—ये डेटा देखकर खुद पैटर्न सीखता है।
एक relatable उदाहरण:
जैसे एक बच्चा बार-बार अलग-अलग फलों की फोटो देखकर सीखता है कि कौन-सा सेब है और कौन-सा आम—वैसे ही Neural Network भी डेटा से खुद सीखना सीखता है।

मूल बातें: Neuron, Weights, Bias, Activation
Neural Network, बहुत सारे छोटे-छोटे ‘न्यूरॉन्स’ (गणना इकाइयाँ) का समूह है।
- Neuron: छोटा decision-maker जिसे इनपुट मिलते हैं।
- Weights (w): हर इनपुट की महत्ता (कितना महत्व देना है)।
- Bias (b): एक छोटा adjustment (जैसे खिचड़ी में नमक का अंतिम टच 😄)।
- Activation Function: तय करती है कि आउटपुट कितना/कैसा निकले (on/off या कितना ज़्यादा)।
किचन analogy:
आप दाल बनाते समय मसालों की मात्रा (weights) adjust करके स्वाद (output) सेट करते हैं; कभी थोड़ा नींबू (bias) जोड़ते हैं ताकि overall स्वाद सही बने; और आख़िर में “खाना बना या नहीं?” जैसी decision लाइन—ये activation जैसा है।
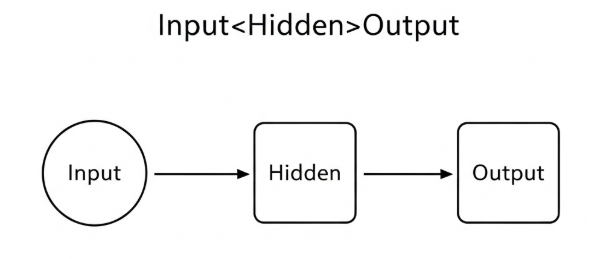
Layers क्या हैं? Input → Hidden → Output
Neural Network कई परतों (layers) से बना होता है:
- Input Layer: डेटा प्रवेश (जैसे इमेज के पिक्सेल, टेक्स्ट की embeddings)।
- Hidden Layers: असली जादू यहीं—बहुत सारे neurons छोटे-छोटे फैसले लेकर जटिल पैटर्न पकड़ते हैं।
- Output Layer: अंतिम उत्तर—जैसे “यह बिल्ली है” या “स्पैम/नॉट स्पैम”।
सोचिए:
- पहली hidden layers basic features पकड़ती हैं (इमेज में किनारे/धार)।
- गहरी layers complex features (आँख, मूँछ, चेहरा) पकड़ती हैं।
- आखिर में “ये बिल्ली है!”—फाइनल verdict।
सीखने की प्रक्रिया: Forward Pass, Loss, Backpropagation
- Forward Pass: डेटा अंदर जाता है → layer दर layer गणना → आउटपुट निकलता है।
- Loss (त्रुटि): आउटपुट और सही जवाब में कितना फर्क है—ये loss बताता है।
- Backpropagation + Gradient Descent: loss देखकर weights-बायस को थोड़ा-थोड़ा बदलते हैं ताकि अगली बार गलती कम हो।
नमक analogy:
पहली बार दाल में नमक कम लगा (loss ज़्यादा)। आप अगली बार थोड़ा बढ़ाते हैं (weights update)। कुछ कोशिशों के बाद स्वाद perfect—यही gradient descent की भावना है।
Activation Functions: Sigmoid, ReLU, Softmax (सरल समझ)
- Sigmoid: आउटपुट 0–1 (जैसे हाँ/ना की संभावना)।
- ReLU: negative को 0, positive वैसा ही (तेज़ सीखने में मदद; ज़्यादातर hidden layers में)।
- Softmax: कई classes में probability बाँटना (जैसे बिल्ली/कुत्ता/पक्षी में से कौन?).
उदाहरण:
ईमेल स्पैम है या नहीं? → Sigmoid ठीक।
इमेज में कई चीज़ों में से एक चुननी है? → Softmax बढ़िया।
Neural Networks के प्रमुख प्रकार
1) Feedforward Neural Network (FNN / MLP)
सबसे बेसिक—डेटा आगे की दिशा में बहता है; structured data के लिए उपयोगी।
- कब? टैबुलर डेटा, बेसिक classification/regression।
2) Convolutional Neural Network (CNN)
इमेज/वीडियो के लिए चैंपियन। Convolution फिल्टर किनारे, टेक्सचर, shapes पकड़ते हैं।
- उदाहरण: फेस अनलॉक, एक्स-रे/एमआरआई detection, फोटो में ऑब्जेक्ट पहचान।
- कब? विज़ुअल कार्य, OCR, autonomous driving में perception।

CNN क्या है? इमेज पहचान की अंदर की कहानी (हिंदी गाइड)
3) Recurrent Neural Network (RNN), LSTM, GRU
सीक्वेंस डेटा (आवाज़, टेक्स्ट, टाइम-सीरीज़) के लिए; पिछले step का संदर्भ आगे ले जाते हैं।
- उदाहरण: स्पीच-टू-टेक्स्ट, मशीन ट्रांसलेशन, स्टॉक-टाइमसीरीज़।
- कब? क्रमवार डेटा जहाँ संदर्भ ज़रूरी है।
4) Transformer (Attention मेकैनिज़्म)
आज का स्टार! Attention से मॉडल तय करता है कि इनपुट के कौन-से हिस्से पर कितना ध्यान देना है। LLMs (जैसे ChatGPT) इसी परिवार से आते हैं।
- उदाहरण: टेक्स्ट जनरेशन, summarization, कोड जनरेशन, मल्टी-मोडल (टेक्स्ट+इमेज) मॉडल।
- कब? NLP/GenAI, long-context समझ, multilingual tasks, विज़न-ट्रांसफॉर्मर।
Training Basics: Data, Epochs, Batch, Regularization
- Data & Labels: जितना साफ़ और विविध डेटा, उतनी बेहतर सीख।
- Epochs: पूरा डेटासेट कितनी बार सीखा गया।
- Batch Size: एक बार में कितने उदाहरणों से वजन अपडेट।
- Overfitting: मॉडल ट्रेन डेटा को रट लेता है—नए डेटा पर गलती।
- उपाय: Regularization (L2), Dropout, Data Augmentation, Early Stopping।
घर की मिसाल:
बच्चा अगर एक ही सवाल बार-बार रट ले, परीक्षा में नए सवाल पर अटक सकता है—यही overfitting है। इसलिए अलग-अलग उदाहरणों से अभ्यास कराना ज़रूरी (data augmentation)।

Evaluation: Accuracy, Precision/Recall, F1, Confusion Matrix
- Accuracy: कुल सही का प्रतिशत—पर असंतुलित डेटा में भ्रामक हो सकता है।
- Precision/Recall: Fraud/बिमारी detection में ज़्यादा meaningful।
- F1-score: precision और recall का संतुलित औसत।
- Confusion Matrix: सही-गलत की 4 खानों वाली सच्ची तस्वीर।
Mini-example:
मरीजों में बीमारी ढूँढ़नी है (rare cases) → सिर्फ accuracy हाई होना पर्याप्त नहीं; recall ज़्यादा महत्त्वपूर्ण।
Hardware, Compute और समय
- GPU/TPU से DL ट्रेनिंग बहुत तेज़ होती है।
- Batch Size/Sequence Length और Model Size से मेमोरी तय होती है।
- शुरुआत में छोटे मॉडल + छोटे डेटासेट पर तेज़ प्रयोग करें—फिर स्केल करें।
Neural Networks कहाँ-कहाँ दिखते हैं?
- मोबाइल कैमरा: Portrait blur, scene detection
- फेस अनलॉक: चेहरा पहचान
- स्पीच: आवाज़ → टेक्स्ट
- OCR/अनुवाद: छपे शब्द → डिजिटल टेक्स्ट → हिंदी/अंग्रेज़ी अनुवाद
- रिकमेंडेशन: आपकी पसंद के मुताबिक वीडियो/प्रोडक्ट सुझाव
- हेल्थकेयर: एक्स-रे, MRI में संकेत पकड़ना

Common Confusions क्लियर
- Neural Network = Deep Learning?
DL आमतौर पर गहरे (deep) Neural Networks को कहते हैं। यानी हर DL, NN ही है—but हर NN deep हो ये ज़रूरी नहीं। - Data Science vs NN?
Data Science में डेटा की सफ़ाई, विश्लेषण, विज़ुअलाइज़ेशन, बिज़नेस इनसाइट्स—NN मॉडलिंग का एक टूल है। - LLM क्या NN है?
हाँ—LLM (जैसे Transformers) Neural Networks से बने बड़े भाषा मॉडल हैं।
Risks और Ethics (संक्षेप में)
- Bias: टेढ़े डेटा से टेढ़े नतीजे—कौन सा डेटा, कैसे कलेक्ट/क्लीन किया गया, पारदर्शिता रखें।
- Privacy: संवेदनशील जानकारी की सुरक्षा।
- Explainability: खासकर हेल्थ/फाइनेंस में “क्यों ऐसा फैसला?” समझना आवश्यक।
- Responsible Use: Deepfake/गलत सूचना से बचाव—नीतियाँ और टूल्स दोनों ज़रूरी।
कैसे शुरू करें? (Beginner Roadmap)
- Python Basics: Numpy, Pandas (डेटा हैंडलिंग)
- ML बेसिक्स: Scikit-learn पर छोटे प्रोजेक्ट (स्पैम क्लासिफ़ायर, हाउस-प्राइस)
- DL स्टेप-अप:
- Keras/TensorFlow या PyTorch से MNIST digits क्लासिफिकेशन
- फिर CNN पर छोटी इमेज-टास्क (cats vs dogs)
- आगे RNN/Transformer से टेक्स्ट टास्क (sentiment)
- Best Practices: train/val/test split, early stopping, augmentation, results reproducibility
- Portfolio: GitHub पर साफ़ README + demo images/gifs; छोटे ब्लॉग/कैप्शन में सीख लिखें।

FAQs (बार-बार पूछे जाने वाले सवाल)
Q1. Neural Network और दिमाग एक जैसे हैं?
A. प्रेरणा दिमाग से है, पर NN एक मैथेमेटिकल मॉडल है—जैविक दिमाग जितना जटिल नहीं।
Q2. Backpropagation क्या है?
A. Loss देखकर weights को उलटी दिशा में adjust करने की विधि—ताकि अगली बार गलती कम हो।
Q3. CNN vs RNN vs Transformer—कब क्या लें?
A. CNN = इमेज/विज़न; RNN/LSTM = सीक्वेंस (आवाज़/टाइमसीरीज); Transformer = टेक्स्ट/लंबा संदर्भ/GenAI और अब विज़न में भी (ViT)।
Q4. इतना डेटा क्यों चाहिए?
A. जटिल पैटर्न समझने के लिए विविध और बड़ा डेटा NN को generalize करने में मदद करता है।
Q5. क्या Neural Network “सोचता” है?
A. ये पैटर्न सीखता है; इंसानी चेतना/इमोशन जैसी सोच नहीं।
Q6. Overfitting कैसे रोकेँ?
A. Regularization, Dropout, Data Augmentation, सही validation, early stopping—ये सब मिलकर मदद करते हैं।
निष्कर्ष
Neural Network को ऐसे समझिए—बहुत सारे छोटे-छोटे निर्णयों का संगम, जो मिलकर बड़ा और समझदार फैसला देता है। सही डेटा, सही डिजाइन और जिम्मेदार उपयोग के साथ NNs आज इमेज, आवाज़, टेक्स्ट, कोड—हर जगह कमाल कर रहे हैं। अब जब कोई CNN, RNN, Transformer बोलेगा—आप आराम से मुस्कुराकर समझा पाएँगे। 😉










