
किसी फोटो में “क्या है?” और “कहाँ है?” जानना काफी नहीं होता—कई बार हमें हर पिक्सेल का सच चाहिए। जैसे एक्स-रे में बीमारी का सटीक फैलाव, सड़क पर लेन की बारीक लाइनें, या खेत में फसल बनाम खरपतवार। यही काम है Image Segmentation का—और इस दुनिया की सुपरस्टार आर्किटेक्चर है U-Net।
मैं, आपकी टेक-दीदी 😊, आज आपको Segmentation और U-Net इतनी आसान भाषा में समझाऊँगी कि आप तुरन्त अपना पहला प्रोजेक्ट शुरू कर सकें!

60 सेकंड में Segmentation समझें
विषयसूची
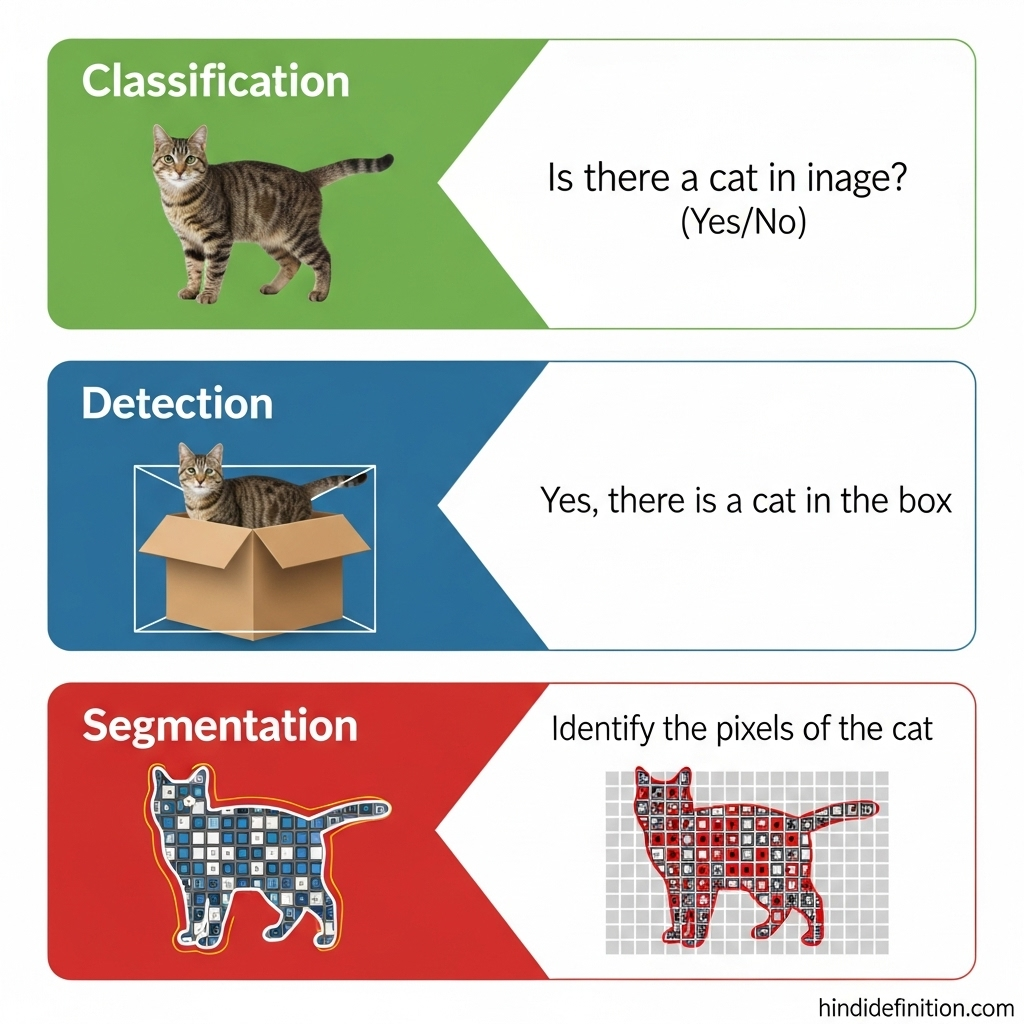
Image Segmentation = इमेज के हर पिक्सेल को एक क्लास देना।
- Classification: “इमेज में बिल्ली है?” (हाँ/ना)
- Detection: “बिल्ली है और यह बॉक्स में है।”
- Segmentation: “बिल्ली के हर पिक्सेल कौन-से हैं?”
कहाँ उपयोग? मेडिकल इमेजिंग, ऑटोनोमस ड्राइविंग, सैटेलाइट मैपिंग, एग्री-टेक, इंडस्ट्रियल QC, AR/Background removal—जहाँ बारीकी मायने रखती है।
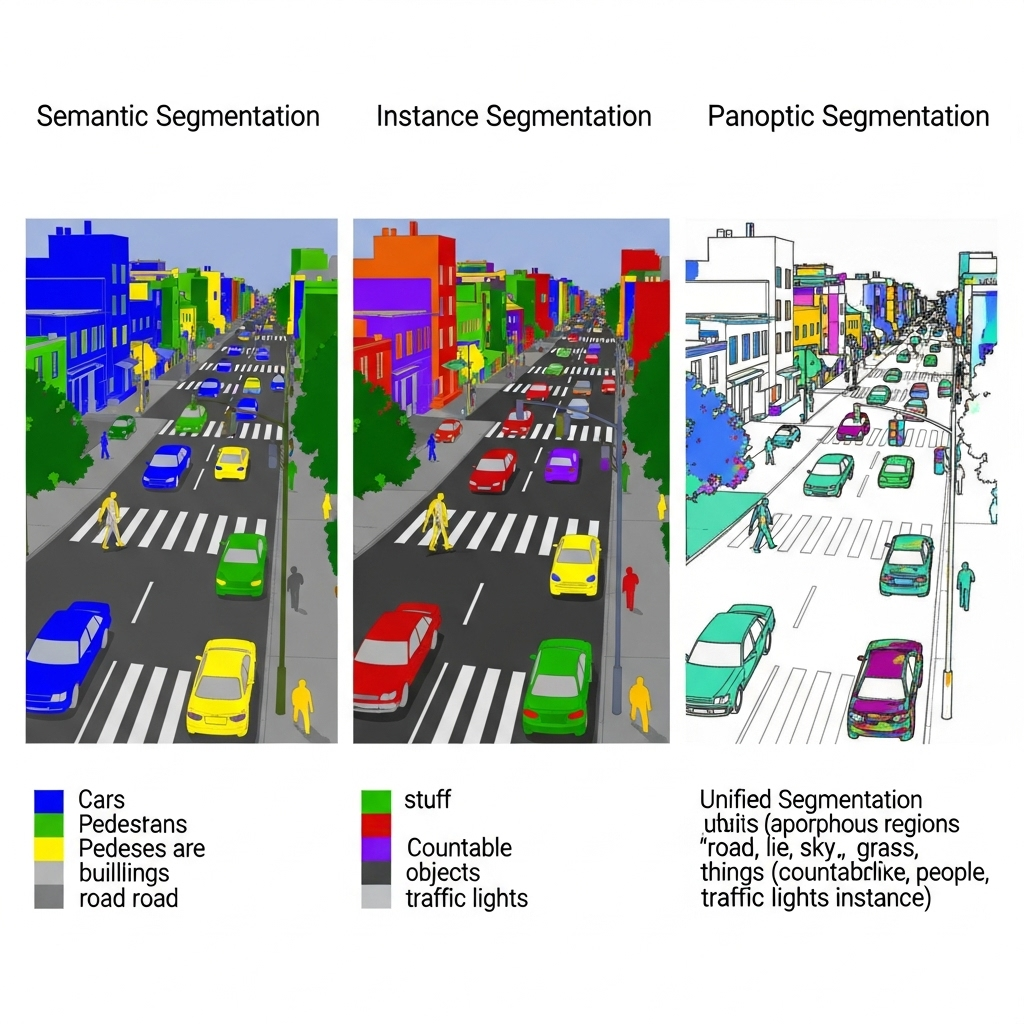
Segmentation के प्रकार: Semantic, Instance, Panoptic
- Semantic Segmentation: हर पिक्सेल को क्लास (जैसे ‘Road’, ‘Car’, ‘Sky’)—एक ही क्लास की सभी कारें एक रंग।
- Instance Segmentation: हर ऑब्जेक्ट का अलग मास्क (Car-1, Car-2)।
- Panoptic Segmentation: Semantic + Instance का कॉम्बो—stuff (road, sky) + things (car-1, car-2) दोनों।
रोज़मर्रा उदाहरण:
सड़क के फोटो में Semantic बताएगा “ये हिस्से रोड हैं”, Instance बताएगा “ये तीन अलग-अलग कारें हैं”, Panoptic दोनों जोड़ देगा।
U-Net क्यों मशहूर है?
U-Net एक Encoder–Decoder आर्किटेक्चर है जिसमें Skip Connections होती हैं।
- Encoder (Downsampling): इमेज से फीचर्स निकालना—कहाँ-कहाँ क्या पैटर्न।
- Decoder (Upsampling): उन्हीं फीचर्स से पिक्सेल-लेवल मास्क दोबारा बनाना।
- Skip Connections: Encoder की बारीक जानकारी सीधे Decoder तक—जिससे बॉर्डर/डिटेल नहीं खोती।
घरेलू मिसाल:
मानिए आप बड़े पोस्टर को मोड़कर रख देते हैं (downsample), फिर खोलकर दीवार पर लगाते हैं (upsample)। अगर बीच में फोल्ड-मार्क (fine details) याद न रहें, पोस्टर गलत दिखेगा। Skip connections उन बारीकियों को संभालकर रखती हैं।
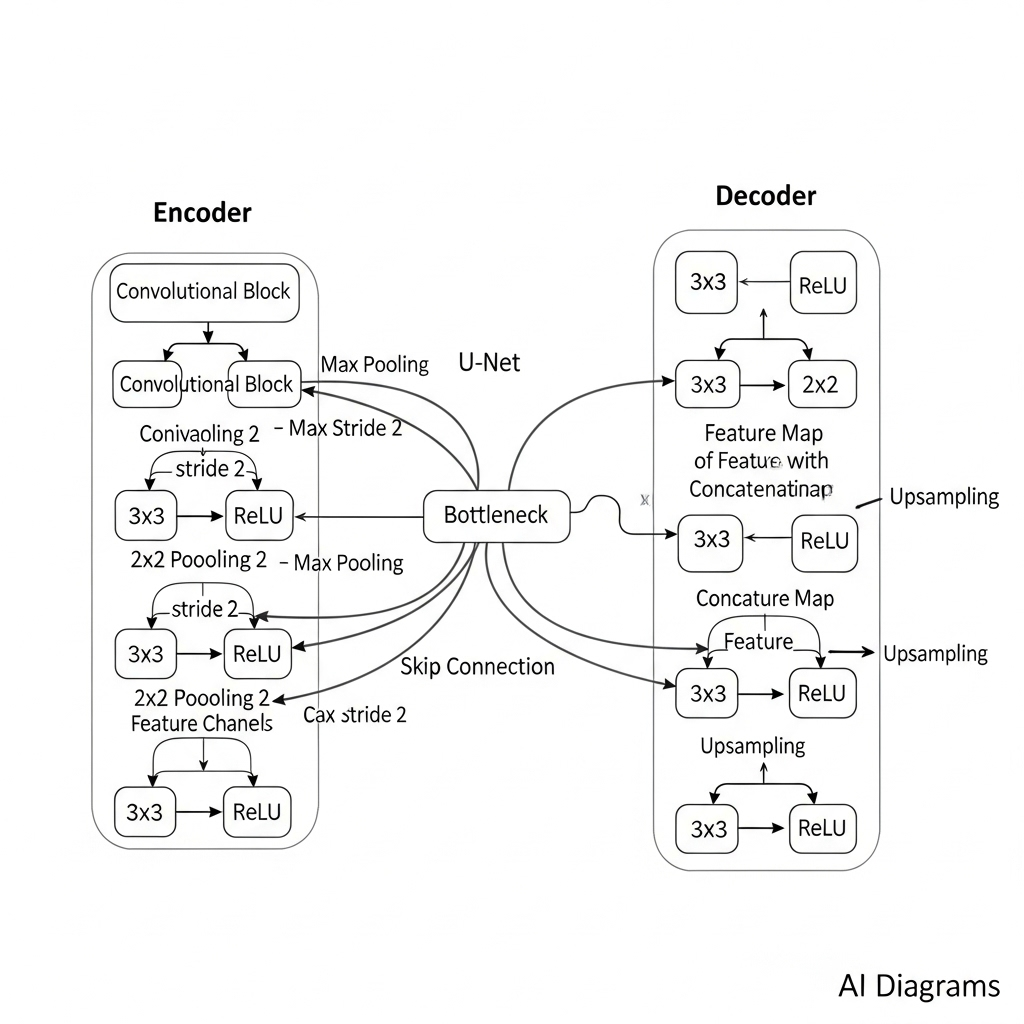
U-Net की रचना: भाग-भाग में
- Input: H×W×C (जैसे 256×256×3)
- Encoder Blocks: Conv→ReLU (या GELU) → Conv→ReLU → MaxPool (साइज घटता, चैनल बढ़ते)
- Bottleneck: सबसे पावरफुल फीचर्स—इमेज का “निचोड़”
- Decoder Blocks: Upsample/Transpose-Conv → Skip Connection से encoder का आउटपुट जोड़ना → Conv→ReLU
- Final 1×1 Conv: जितनी क्लास, उतने चैनल; Sigmoid (binary) या Softmax (multi-class)
क्यों काम करता है?
क्योंकि U-Net लोकल + ग्लोबल दोनों जानकारी पकड़ता है और स्किप्स की वजह से बॉर्डर तेज़ रहते हैं—मेडिकल मास्किंग में यही तो चाहिए!
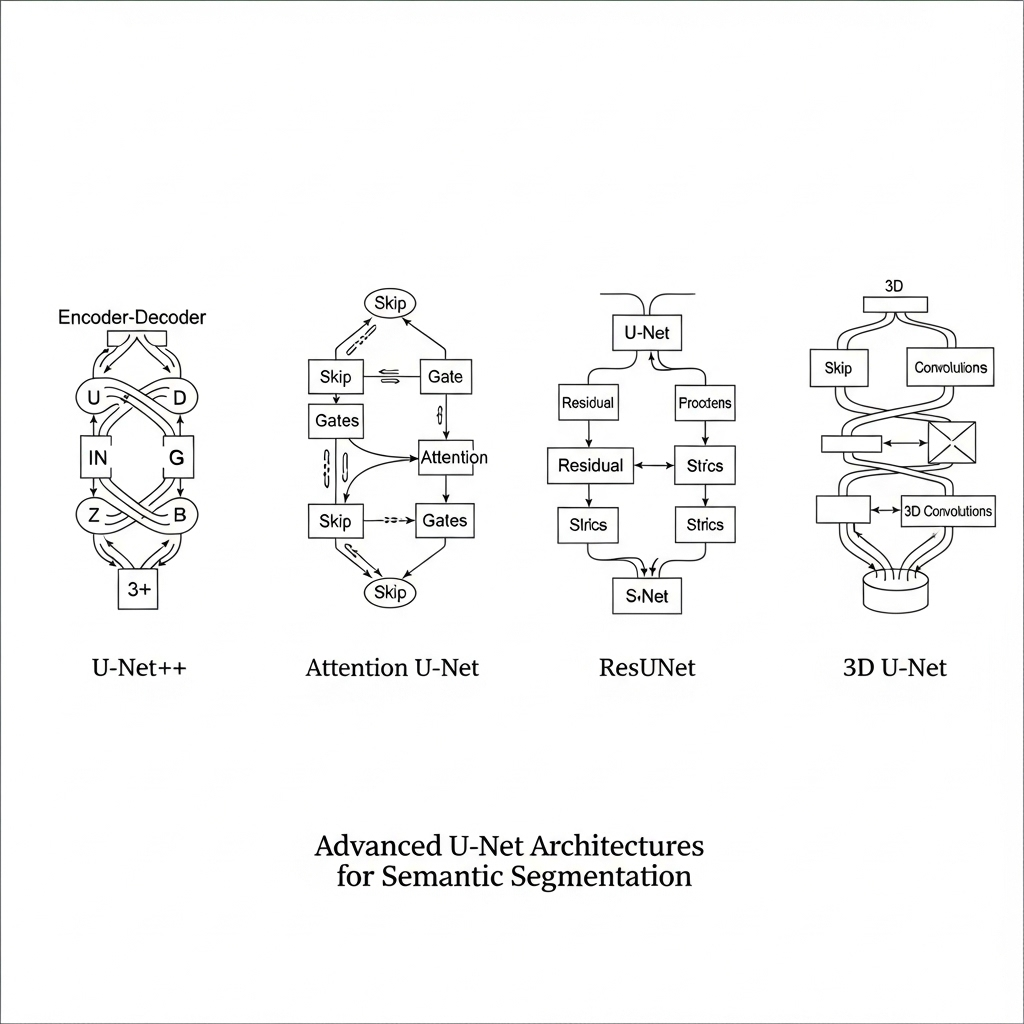
U-Net के लोकप्रिय वेरिएंट
- U-Net++ / Nested U-Net: स्किप पाथवे और रिफाइन्ड कनेक्शंस—बारीक मास्क।
- Attention U-Net: कहाँ ध्यान दें—यह खुद सीखता है (attention gates)।
- ResUNet / UNet3+: ResNet-स्टाइल ब्लॉक्स, और बेहतर फीचर फ्यूज़न।
- 3D U-Net: वॉल्यूमेट्रिक डेटा (CT/MRI) के लिए 3D कंवॉल्यूशन।
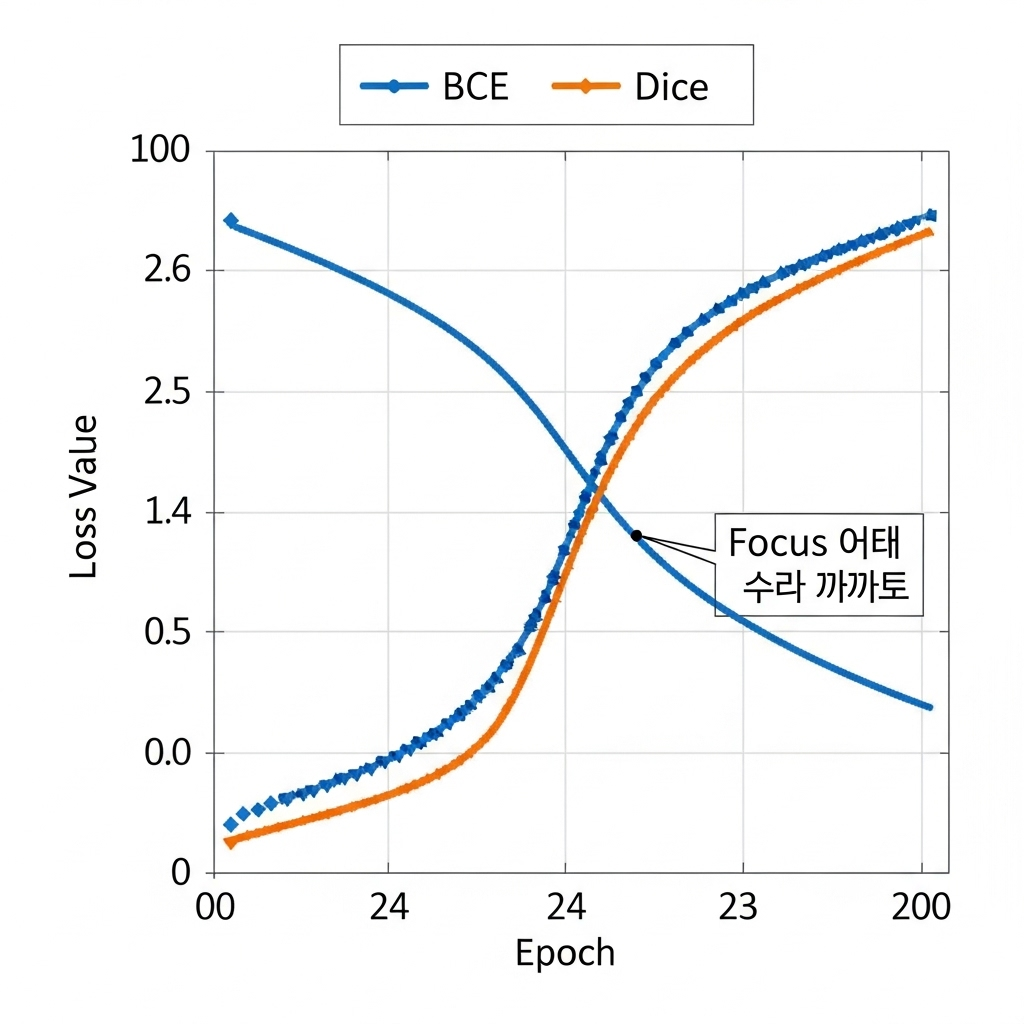
Loss Functions: Dice vs Cross-Entropy?
Segmentation में class imbalance आम है (object छोटा, background बड़ा)। इसलिए सही loss चुनना अहम:
- Binary Cross-Entropy (BCE): बाइनरी/दो-क्लास के लिए बेसिक।
- Categorical Cross-Entropy: मल्टी-क्लास में।
- Dice Loss: ओवरलैप (Dice coefficient) पर आधारित—छोटी क्लासों के प्रति संवेदनशील।
- Jaccard/IoU Loss: ओवरलैप आधारित—IoU बेहतर करने में मदद।
- Focal Loss: hard examples पर फ़ोकस—imbalance में कारगर।
- Tversky/Focal-Tversky: false positives/negatives का संतुलन अपने हिसाब से।
टिप: मेडिकल/छोटी ऑब्जेक्ट क्लास के लिए BCE + Dice या Focal-Tversky अक्सर बढ़िया काम करती हैं।
Metrics: कैसे मापें सटीकता?
- IoU (Jaccard): इंटरसेक्शन/यूनियन—जितना बड़ा, उतना अच्छा।
- Dice Coefficient (F1-समान): ओवरलैप माप—खासकर छोटी क्लासों में sensitive।
- Pixel Accuracy: कुल सही पिक्सेल—imbalance में भ्रामक हो सकता है।
- mIoU / mDice: हर क्लास का औसत—fair तुलना के लिए ज़रूरी।
रियल-लाइफ़ सोच: कैंसर क्षेत्र छोटा है; Pixel Accuracy बहुत high आ सकती है पर Dice/IoU सच्चाई बताएगा।
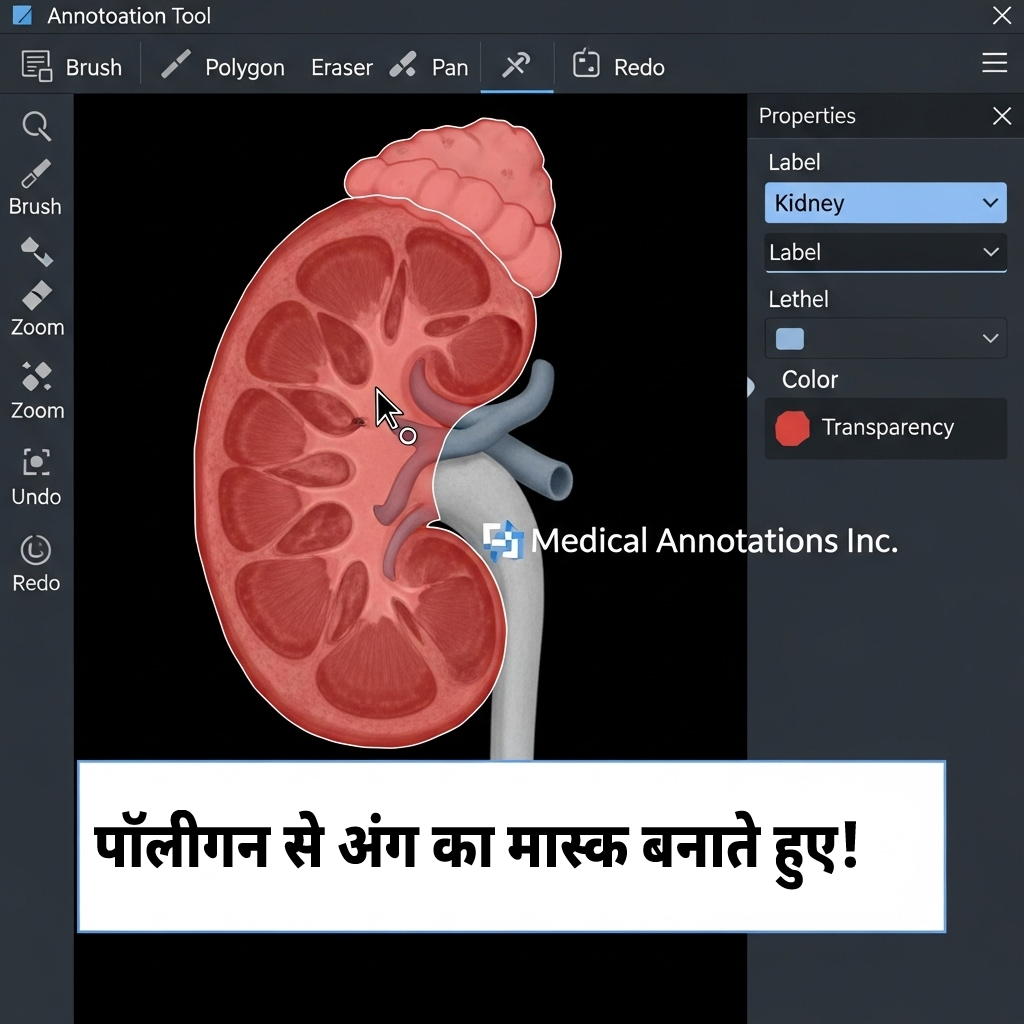
डेटा, एनोटेशन और फॉर्मेट
- Annotation Tools: CVAT, Labelbox, Supervisely, VGG Image Annotator—polygon/brush से मास्क बनाएं।
- फ़ॉर्मेट:
- Binary mask (PNG)—0/1 पिक्सेल।
- Indexed mask (PNG)—हर क्लास अलग इंडेक्स।
- COCO RLE—run-length encoding (स्पेस बचाने को)।
- Splits:
train/val/test—संतुलित और विविध रखें।
Data Augmentation (जादू, पर समझदारी से)
- ज्योमेट्रिक: फ्लिप, रोटेशन, स्केल, क्रॉप, इलैस्टिक-डीफॉर्मेशन (U-Net पेपर में प्रसिद्ध)।
- कलर: ब्राइटनेस/कॉन्ट्रास्ट/ह्यू—पर मेडिकल में सावधानी!
- CutMix/Copy-Paste: छोटे ऑब्जेक्ट्स बढ़ाने को।
- Patch-based Training: बड़ी इमेज को छोटे पैच में बाँटकर ट्रेनिंग—मेमोरी बचती है।
घर-परिवार analogy: सिर्फ़ एक ही तरह के सवाल रटेंगे तो ओवरफिटिंग; अलग-अलग एंगल/लाइटिंग (augmentation) से असली समझ आती है।
Post-Processing: मास्क और सुंदर कैसे दिखे?
- Thresholding: Sigmoid/Softmax आउटपुट को 0/1 में बदलना।
- Morphological Ops: opening/closing से शोर हटाना, बॉर्डर स्मूथ।
- Connected Components: अलग-अलग इंसटेंस अलग करना।
- CRF/Graph-based: किनारों को और sharp बनाना (जरूरत हो तो)।
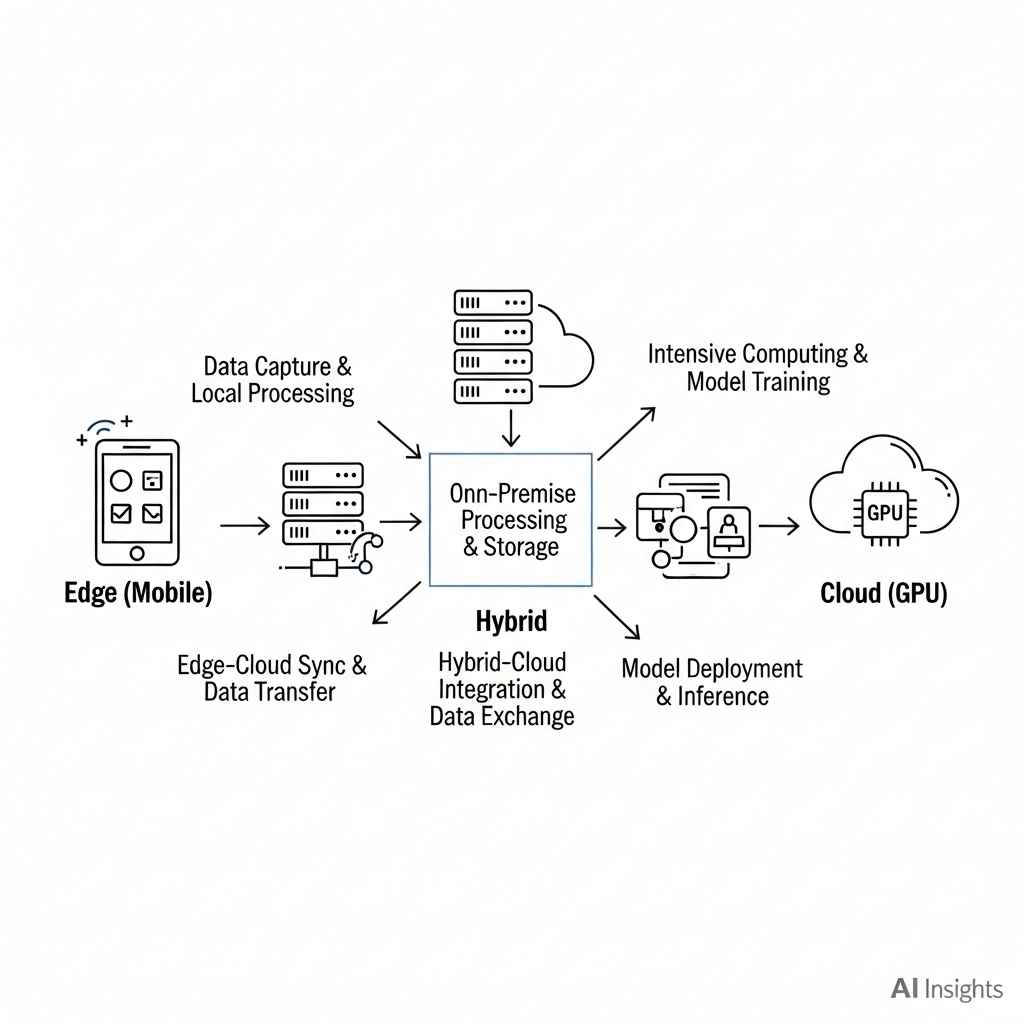
Speed vs Quality: डिप्लॉयमेंट की हकीकत
- एज/मोबाइल: हल्का U-Net, Quantization (INT8), TFLite/ONNX/CoreML।
- क्लाउड/सर्वर: बड़े मॉडल, बैच प्रोसेसिंग, GPU/TPU।
- हाइब्रिड: कैमरा पर रन → summary/alert क्लाउड को—लैटेंसी कम, प्राइवेसी बेहतर।
Detection vs Segmentation vs Panoptic—कब क्या?
| जरूरत | सुझाव |
|---|---|
| सिर्फ़ “क्या है?” | Classification |
| “क्या + बॉक्स” | Detection (YOLO/Faster R-CNN) |
| पिक्सेल-लेवल सीमा/क्षेत्र | Semantic Segmentation (U-Net) |
| पिक्सेल-लेवल + हर ऑब्जेक्ट अलग | Instance/Panoptic (Mask R-CNN/Hybrid) |
आम गलतियाँ और फिक्स
- Imbalance (object छोटा): Dice/Focal/Tversky loss, oversampling, targeted crops।
- Blurry edges: Higher-res ट्रेनिंग, बेहतर augmentation, post-processing।
- Overfitting: ज़्यादा augmentation, dropout, early-stopping, mixup/cutmix।
- Wrong labels: Annotation audit—5-10% डेटा cross-check।
- Metric trap: केवल Pixel Accuracy नहीं; mIoU/Dice पर फोकस।
Mini Blueprint: “Road Lane Segmentation” (U-Net)
- डेटा: सड़क इमेज + lane मास्क (binary)
- Preprocess: resize (512×512), normalization
- Augmentation: flip, slight rotate, brightness (सीमित)
- मॉडल: U-Net (encoder=pretrained ResNet-34/50 भी ले सकते हैं)
- Loss: BCE + Dice; Metric: IoU/Dice
- Train: 50-100 epochs (early-stopping), best model save
- Post-process: threshold 0.5, morphology open/close
- Deploy: ONNX/TFLite; मोबाइल कैमरा फीड पर रन
Use-Cases (जहाँ Segmentation चमकती है)
- मेडिकल: ट्यूमर/ऑर्गन सीमाएँ, घाव-सेगमेंटेशन
- ऑटोमोबाइल: रोड/लेन/ड्राइवलाइन, ड्राइवएबल एरिया
- एग्री-टेक: फसल बनाम खरपतवार, फल गिनना (instance)
- सैटेलाइट/GIS: बिल्डिंग/जल-क्षेत्र, भूमि-आवरण मैपिंग
- इंडस्ट्रियल QC: माइक्रो-डिफेक्ट, सोल्डरिंग जॉइंट्स
- AR/क्रिएटिव: बैकग्राउंड रिमूवल, लाइव मास्किंग

Beginners के लिए छोटे-छोटे स्टेप्स
- Python + Numpy/Pandas की हल्की पकड़
- PyTorch/Keras से U-Net का रेडी टेम्पलेट
- Open-source datasets (e.g., Kaggle nuclei/road) पर POC
- Weights & Biases/MLflow से ट्रेनिंग-लॉग—क्या काम करता है, क्या नहीं
- GitHub पर README + sample images/gifs—पोर्टफोलियो बनेगा
निष्कर्ष
Segmentation का मकसद है हर पिक्सेल की कहानी बताना—और U-Net इसे आसान, तेज़ और सटीक बनाता है। Encoder-Decoder + Skip Connections की वजह से बारीक बॉर्डर और सूक्ष्म पैटर्न बचते हैं। सही Loss/Metric, समझदार Augmentation, और हल्के-फुल्के Post-Processing से आप मेडिकल से लेकर मैपिंग और मोबाइल-AR तक शानदार नतीजे पा सकते हैं। छोटे POC से शुरुआत करें—धीरे-धीरे आप भी पिक्सेल-लेवल जादूगर बन जाएँगे! ✨











